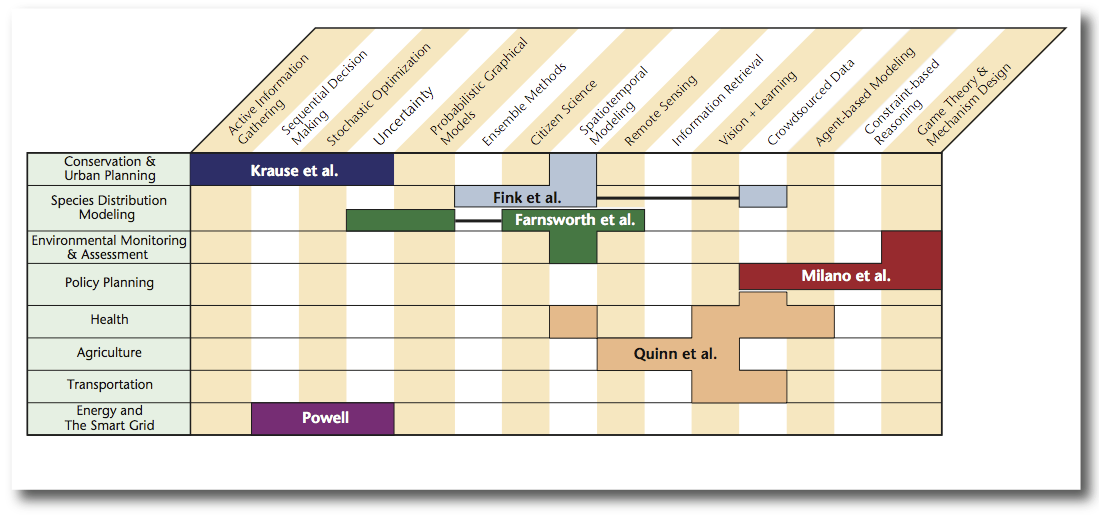
This week in Québec City the Twenty-Eighth AAAI Conference is being held and for the fourth year running there is a special track on Computational Sustainability. The range of talks look at ways to apply and extend ideas in Artificial Intelligence and Machine Learning for solving complex problems in Electric Vehicle Management, Bird Tracking, Disease Mapping, Power Management and Urban Emergency Preparedness.
You can see the full abstracts for the talks from the whole conference including the CompSust track online here. Also, if you subscribe or have access to AI Magazine, the magazine publication for AAAI, you can see some high level articles in the next two issues on the range and depth of CompSust research.
If you have research in this area that you want to submit then you’re in luck, due to AAAI changing it’s schedule from summer to winter the next AAAI CompSust deadline is just five weeks away! (Abstract:Sep10, Paper:Sep15) (Ok, so it’s a good thing if you have something ready to submit.) Good luck!
Topics in Sustainability and Artificial Intelligence of articles in the special CompSust 2014 issues of AI Magazine.
Happy New Year CompSust researchers! If you are in the Atlanta area take a look at this workshop being hosted by Georgia Tech. It looks like a good opportunity to build local awareness and community for CompSust problems and solutions.
Sustainability starts with the individual and extends to buildings, neighborhoods, cities, and regions. Workshop participants will simultaneously explore new approaches to achieving sustainable growth that can be enabled through innovations in computation, as well as the computational technologies themselves. Relevant computational technologies include data analytics, modeling and simulation, optimization, high performance computing, and distributed computing platforms. The event will include a brief overview to frame the discussion, a series of representative presentations covering ongoing research in sustainability challenges and computational technologies, breakout discussions to define overarching themes and synergies, and a networking reception to enable further discussion among researchers. While time does not permit everyone to give a formal presentation, discussion sessions are included to enable others to briefly discuss their research interests.
Computational Sustainability Workshop Date:Thursday, January 30, 2014
Time: 1-6pm
Location: Georgia Tech Hotel
Some news for researchers in Computational Sustainability updated throughout the month. If you know of relevant news for researchers working at the intersection of Computer Science and Sustainability share it with us in the comments, on Google+ in the CompSust community, or join the CompSust mailing list.
Workshop: SustainIT 2013 – The Third IFIP Conference on Sustainable Internet and ICT for Sustainability is an interdiscplinary conference between industry and academia to address topics both of the significant energy consumption of computing technology and as a potential actor in steering a more clever usage of energy resources.
Deadline: passed
Time and Place: October 30-31, Palermo, Italy.
Workshop: The First Workshop on Machine Learning for Environmental Sustainability (EnvSustML 2013) is collocated with the Asian Machine Learning Conference and aims to bring machine learning and data mining researchers and experts in the environmental domain together to tackle challenges towards environmental sustainability Deadline: Sept 30, 2013
Time and Place: November 13-15, 2013. Australian National University, Canberra, Australia
Knowledge of the distribution and ecological associations of a species is a crucial ingredient for successful conservation management, biodiversity and sustainability research. However, ecological systems are inherently complex, our ability to directly observe them has been limited, and the processes that affect the distributions of animals and plants operate at multiple spatial and temporal scales.
Species distribution model estimates (colorbar: relative probability of occurrence) across the West Hemisphere from massively crowdsourced eBird data.
Very recently, large citizen science efforts such as eBird, a very successful crowdsourcing project by the Cornell Lab of Ornithology that engages citizen scientists and avid birders, is enabling for the first time world-wide observations of bird distributions. eBird has collected more then 100 millions of bird observations to date from as many as 100 thousand human volunteers and submissions (checklists) continue to grow with an exponential rate. With this wealth of evidence comes a plethora of challenges as the data collection and sampling designs are unstructured, follow human activities and concentrations, and are subject to observer and environmental biases. For example, sparsely populated states in the US, such as Iowa and Nevada, have very low frequency of observations whereas East and West Coast states have the highest continental counts. Furthermore, temporal variability and biases are also evident as annual submission rates peak during spring and fall migration which is the most exciting times for birders to observe multiple species.
In our AAAI paper, we propose adaptive spatiotemporal species distribution models that can exploit the uneven distribution of observations from such crowdsourcing projects and can accurately capture multiscale processes. The proposed exploratory models control for variability in the observation process and can learn ecological, environmental and climate associations that drive species distributions and migration patterns. We offer for the first time hemisphere-wide species distribution estimates of long-distance migrants (Barn Swallow, Blackpoll Warbler, and Black-throated Blue Warbler in Figure above), utilizing more then 2.25 million eBird checklists.
Until recently, most biodiversity monitoring programs that collect data have been national in scope, hindering ecological study and conservation planning for broadly distributed species. The ability to produce comprehensive year-round distribution estimates that span national borders will make it possible to better understand the ecological processes affecting the distributions of these species, assess their vulnerability to environmental perturbations such as those expected under climate change, and coordinate conservation activities.
Citation:
D. Fink, T. Damoulas, J. Dave, (2013). Adaptive Spatio-Temporal Exploratory Models: Hemisphere-wide species distributions from massively crowdsourced eBird data. AAAI 2013, Washington, USA.
This is one of our series of posts on the latest research in Computational Sustainability being presented at conferences this summer. This time Theo Damoulas, a Research Associate in Computer Science, and a member of the Institute for Computational Sustainability, at Cornell University tells us about their new paper at AAAI in Washington this month.
The Twenty-Seventh AAAI Conference on Artificial Intelligence (AAAI-13) convenes next week in Bellevue, Washington USA. For the third consecutive year there will be a special track on Computational Sustainability, a nascent and growing field of computing that is concerned with the application of computer science principles, methods, and tools to problems of environmental and societal sustainability. This is not a one-way street, however, because sustainability problems force computer scientists into new theory, as well as new practice. For example, sustainability problems require extraordinary attention to solution robustness (e.g., so that a so-called optimal solution doesn’t catastrophically fail with an environmental change) and issues of uncertainty, ranging from uncertainties in environmental sensor readings to uncertainties in the budget awarded by a state legislative body for wildlife management!The 16 papers of the Computational Sustainability (CompSust) track of AAAI (http://www.aaai.org/Conferences/AAAI/2013/aaai13accepts.php#Sustainability) cover sustainability problems in natural environment, to include various forms of resource management (e.g., species management, wildfire control), and the built environment (e.g., smart grid, building energy usage). The CompSust presentations are arranged in four presentation sessions, all on Thursday, July 18, 2013. These sessions are organized by AI themes of MDPs and sequential processes, optimization and search, data mining, and multi agent systems.As in the past, the Computing Community Consortium (CCC) is graciously supporting best paper awards for the CompSust track, which will be announced at the opening ceremony on Tuesday, July 16.
Tamarisk (Tamarix parviflora) also known as Salt Cedar in Lower Owyhee River, OR. Photo: C.C. Shock, Oregon State University.
If you have a very large decision making problem and want to find an approximately optimal policy, one of the best ways is often to use simulated trajectories of states, actions and utilities to learn the policy from experience.
In many natural resource management problems running simulations is very expensive because of the complex processes involved and because of spatial interactions across a landscape. This means we need an approximate planning algorithm for MDPs that minimizes the number of calls to the simulator. Our paper at AAAI presents an algorithm for doing that.
Example Problem : Invasive Species Management
One example of a natural resource management problem with this kind of challenge is management of invasive river plants. For example, Tamarisk is an invasive plant species originating from the Middle East which has invaded over 3 million acres of land in the Western United States. It outcompetes local plants, consumes water and deposits salt into the soil. This pushes out native grass species, fundamentally changes the chemistry soil and alters an ecosystem that many other species rely on (read more : studies of Tamarisk by NASA; how the Tamarisk Collective is removing Tamarisk and restoring riparian ecosystems). Dropped leaves also create a dry layer of fuel that increases the risk of fire in the already fire-prone West.
Seeds from plants can spread up or down the river network leading to a huge number of reachable states. There is a choice of treatment actions available in each part of the river: we can eradicate invading plants and/or reintroduce native ones. Each treatment action has a cost, but the more expensive treatments are more effective at supplanting the invading plants.
The Planning Problem
The planning problem is the following: Find the optimal policy for performing treatments spatially across a river network and over time in order to restore the native plant population and stay within a given budget level.
This problem can be represented as a Markov Decision Process (MDP) but it very quickly becomes intractable to solve optimally for larger problems. Ideally we want to find a policy with guarantees about how far it is from the optimal solution. PAC-MDP learning methods provide such guarantees by using long simulations to converge on a policy that is guaranteed to be within a given distance of the optimal policy with some probability (see Sidebar: What is an MDP? What does PAC-MDP mean?).
Most of the existing PAC-MDP methods look at a sequence of simulated actions and rewards and rely on revisiting states many times over and over to learn how to act optimally in those states. This does not fit the ecosystem management problem. In reality, we begin in a particular starting state S, in which the ecosystem is typically in some undesirable state far from its desired balance. The goal is to find a policy for moving to a world where Sdoes not occur again.
Our Approach
Our paper improves upon the best approaches for doing approximate planning in large problems in two ways :
It obtains tighter confidence intervals on the quality of a policy by incorporating a bound on the probability of reaching additional (not-yet-visited) states. These tighter intervals mean that fewer simulations are needed.
It introduces a more strategic method for choosing which state would be best to sample next by maintaining a discounted occupancy measure on all known states.
Our work is based on the idea of being able to restart planning from a fixed start state at any time. This idea was originally put forward by Fiechter in 1994 [3]. However, many important innovations have been made in PAC-MDP community which we apply to our problem.
A fundamental feature of many PAC-MDP algorithms is optimism under uncertainty. That is, if there are some states we’ve never encountered or evaluated, then we assume they are high value states. This encourages the algorithm to try to reach unknown states and find out their true value. If such a state does indeed have high value then we benefit directly; if it’s a bad state, then we learn quickly and become less likely to visit the state again. For optimism under uncertainty to work, we need to have an estimate of how likely we are to encounter any particular state over time.
One way to do this is with a confidence interval on the probability for reaching a state. The confidence interval can be computed based on how many times we’ve visited that state in previous simulations. The confidence intervals used in previous algorithms are quite loose. Their width typically depends on the square root of the number of states in the the state space. In spatial ecosystem management problems the state space is exponentially large, so this leads to very wide intervals. However, another property of real-world problems can help us. Typically, when we apply an action in a state, the set of possible resulting states is small. This means that only a small fraction of all the states will actually be reached over the planning horizon. So we can use the Good-Turing estimator of missing mass[5] to put an upper bound on the total probability of all the states we have never visited. We integrate this upper bound into the existing confidence bounds and get a tighter one that better represents when to stop exploring.
Since the key performance cost that we are trying to minimize is the cost of invoking the simulator, the key is to invoke the simulator on the most interesting state at each time step. The second advance in our paper presents a new way to define “most interesting state” by using an upper bound on the occupancy measure. The occupancy measure of a state is essentially an estimate of how important a state will be given how likely we are to visit it and how far it is from the starting state. More precisely, it is the discounted probability that the optimal policy will occupy the state summed over all time, starting from a fixed starting state. We can compute and update this occupancy measure by dynamic programming during planning. Our key observation is that we can estimate the impact of choosing to explore some state K with action A over another in an efficient way. We compute just the impact locally on the confidence interval for the value Kweighted by its occupancy measure. This lets the algorithm focus exploration on the most promising state-action pairs.
We ran our algorithm on four different MDPs including a form of the invasive species river network described above and compared the results to the optimal solutions and results from some other algorithms. We found that our approach requires many fewer samples than previous methods to achieve similar performance. The algorithm does this while maintaining standard PAC bounds on optimality.
If you want to know more you can read our paper here. To take a look at the invasive species river network problem yourself there is a more detailed problem definition and downloadable code from this year’s RL planning competition which included our problem as one of the test domains.
This is one of our series of posts on the latest research in Computational Sustainability being presented at conferences this summer. This time Mark Crowley, a Postdoc in Computer Science at Oregon State University tells us about their new paper at AAAI in Bellevue, Washington, USA this July which has a special track on Computational Sustainability research.
Sidebar: What’s an MDP? What does PAC-MDP mean?
A Markov Decision Process(MDP)[1,2] is a standard mathematical formulation for decision making problems containing states describing the world, actions that can be taken in each state, rewards that represent the utility obtained for taking an action in a given state and dynamics which define a conditional probability of transitioning from one state to another given a particular action. The solution to an MDP is a policy that tells for each state what action to take in that state in order to optimize the long-term cumulative reward. Given an MDP we can define the value of a policy as the expected reward obtained by following the policy over an infinite planning horizon discounted so that states farther in the future have less impact on the value.
There is a wide literature on solving MDPs exactly. The computational cost of these methods scales as the product of the number of actions times the square of the number of states. One community of approximate method that are well studied are the Probably Approximately Correct MDP (PAC-MDP) methods[3,4]. These methods take the idea of PAC estimators from statistics and apply them to estimating the value function of a policy. Essentially, an algorithm for learning a policy is said to be PAC-MDP if we can show that there is at least a probability (1-δ) chance that the value of the policy is within ε of the value of the optimal policy. Further, the algorithm must be efficient: It must halt and return its policy within an amount of time that grows only polynomially in the sizes of the input variables.
References
Bellman, R. 1957. Dynamic Programming. New Jersey: Princeton University Press.
Puterman, M. 1994. Markov Decision Processes: Discrete Stochastic Dynamic Programming. Wiley Series in Proba- bility and Mathematical Statistics.Wiley.
Fiechter, C.-N. 1994. Efficient Reinforcement Learning. In Proceedings of the Seventh Annual ACM Conference on Computational Learning Theory, 88–97. ACM Press.
Strehl, A., and Littman, M. 2008. An Analysis of Model- Based Interval Estimation for Markov Decision Processes. Journal of Computer and System Sciences 74(8):1309–1331.
Good, I. J. 1953. The Population Frequencies of Species and the Estimation of Population Parameters. Biometrika 40(3):237–264.
A group of bar-tailed godwits photographed in Songdo, Korea. Photo: Judit Szabo.
The earth is facing an extinction crisis, with some estimates claiming that almost half of the world’s existing species may be extinct within the next 100 years. Conservation of biodiversity has never been more important, but the science of conservation is very much in its infancy, with a lot to learn from other fields, including Artificial Intelligence. Biological systems are stochastic, difficult to observe, and subject to external influences that make precise predictive modelling difficult. The traditional response to uncertainty has been to “collect more data” with the goal of eventually designing a management strategy to protect the species once and for all.
However more recently this approach has been largely rejected, as delaying effective management action while monitoring is completed can mean a species goes extinct before any action is taken. The current best practice is adaptive management (AM), a process that executes the best management action based on current knowledge, observes how the system responds to the action, and uses this feedback to plan the next action. This integrated process of monitoring and management will be familiar to many in AI as the classic exploration/exploitation trade-off encountered in learning algorithms such as reinforcement learning. Indeed, the cutting edge modelling method for adaptive management problems is to use a method drawn from AI, namely Partially Observable Markov Decision Processes (POMDPs) (for details see below, Sidebar: What’s a POMDP?).
Tidal mudflats in northeastern Asia are critical habitat for the shorebirds of the East Asian-Australasian flyway. Major threats to the birds are coastal development (the new city of Songdo, Korea, can be seen being built in the background of this photo) and sea level rise, which threatens to inundate the mudflats permanently, leaving insufficient habitat for the birds. Photo: Judit Szabo.
In our IJCAI paper, we address a limitation of POMDPs that restricts their use in conservation. Biological systems change over time in response to climate change, but current AM methods (including POMDPs) are not able to plan for non-stationary systems. Current methods assume that there is one ‘true’ model of the world, and by collecting enough data, we will eventually converge on the ‘truth’. This is call a stationary model. However, if the world is changing, then collecting more data may never converge to a model. We use a work-around of creating a POMDP that considers a suite of candidate stationary models representing the effects of future change (in our case, sea level rise) on a population, and maintains a belief about the likelihood that a model is the true model at a given time. As the sea level rises, the POMDP planner can ‘switch’ between candidate models once the observations suggest that such a change has occurred.
As a case study, we consider the effects of rising sea level on 10 declining migratory bird species that depend upon low-lying mudflats to provide the food they need to complete their migration. As the sea level rises, these habitats may become inundated so that the birds cannot complete the migration (4) (read more about sea level’s effect on shorebird populations in the East Asian-Australasian flyway here.) We model the AM problem as a POMDP with the workaround described above, and compute when and where action on sea level rise is required to best protect the birds. We present the paper as a data challenge, and offer flyway network data for 10 species of migratory shorebird for the AI community to develop. We present a data challenge as our method only solves relatively small flyway networks and has high runtimes. Because our workaround and the AM approach are actually simplified POMDPs (they are called hmMDPs), there is room for AI researchers to develop custom solvers that exploit the simplifications, allowing us to find conservation strategies for larger and more realistic networks.
Presentation
Want to know more? If you’re going to IJCAI in Beijing in August, come and see our poster and talk to us. Our full paper and the files for the data challenge are also available for download here. Date: Wednesday August 7, 2013 Location and time: Planning and Scheduling session (8:30-9:45am).
This is one of our series of posts on the latest research in Computational Sustainability being presented at conferences this summer. This time Sam Nicol, a Postdoc at CSIRO Ecosystem Sciences in Australia tells us about their new paper at IJCAI in Beijing this August.
Sidebar: What’s a POMDP?
For the uninitiated, POMDPs are discrete time stochastic control processes that are used to make decisions in situations where the outcomes are partially controlled by chance and partly by the actions of an agent. In particular, POMDPs have the feature that the managing agent cannot directly observe the true state of the system, and must rely on observations of some other proxy variable to make decisions. The POMDP agent is effectively asking: “what is the best action that I can implement today to achieve my future goal, given that I know that the system is stochastic and the data I’m receiving from observing the system is noisy?” POMDPs appear in a surprising number of places. The most famous real-world example is using POMDPs to assist people with dementia complete simple tasks like hand-washing (2). POMDPs have also been used in conservation, for example for determining how much survey effort should be dedicated to looking for cryptic species like the Sumatran tiger (3).
References:
Chadès, I., Cawardine J., Martin, T., Nicol, S., Sabbadin, R., Buffet, O. (2012). MOMDPs: A solution for modeling adaptive management problems. Proc. of the AAAI-12. http://www.aaai.org/ocs/index.php/AAAI/AAAI12/paper/view/4990
Hoey, Jesse ; Bertoldi, Axel von ; Poupart, Pascal ; Mihailidis, Alex (2007) Assisting persons with dementia during handwashing using a partially observable Markov decision process.. The 5th International Conference on Computer Vision Systems, 2007 doi:10.1016/j.cviu.2009.06.008
Chadès, I., McDonald-Madden, E., McCarthy, M.A., Wintle, B., Linkie, M., Possingham, H.P. (2008). When to stop managing or surveying cryptic threatened species. Proc. Natl. Acad. Sci. U.S.A. 105 (37): 13936-40. doi: 10.1073/pnas.0805265105
Iwamura, T., Possingham, H., Chadès, I., Minton, C., Murray, N., Rogers, D., Treml, E., Fuller, R. (2013) Migratory connectivity magnifies the consequences of habitat loss from sea-level rise for shorebird populations Proc R Soc B 280: 20130325
There are a number of events this summer for researchers in Computational Sustainability to meet and share their ideas. Here are just a few I’m aware of, if you know of other meetings or related events let us know in the comments!
We’re going to be inviting some authors from upcoming conferences to write a post for the blog explaining their work to be posted in the near future. If you have a paper at this year’s AAAI or IJCAI and are willing to write a post get in touch with me crowley@eecs.oregonstate.edu. The idea is to have high level descriptions of some of the variety and depth of research going on at the intersections of computation, ecology, optimization, sustainability and machine learning. Hopefully, the writeups can be short and understandable by the general public while providing a enough information for experts to get the general idea of the approach being used. Pretty pictures and real world examples encouraged!
Community
Google+ is really becoming an online home for many scientific communities. Two of the largest Community groups are general science based both with over 80,000 people sharing news and talking about science. One of them recently had an interesting live video forum with Al Gore about climate change. There are also other more focussed groups that are very relevant to our community and regularly have fascinating content: BioCultural Landscapes & Seascapes, Citizen Science Projects and Machine Learning for example. Our own CompSust G+ community is small but we haven’t had a lot of content. So, if you are on G+ and find interesting stories or have updates and thoughts on your own research I encourage you to share it to our community or to share links to groups you find useful.
The conference is meant to be a way for the Operation Research community to reach out to Computer Science and Artificial Intelligence researchers. The solution methods most commonly used are Integer Programming, Linear Programming and local search methods which are referred to as ‘meta-heuristics’. The focus is largely on exact optimization results but there is a growing amount of work on approximate solutions as well.
One exciting thing is there is a lot of interaction between this community and actual power supply or water management utilities in the United States. So it if you aren’t in this community it may be useful to consider comparing this work with your own learning and optimization methods on their problems or to compare to their methods. The abstracts are definitely worth a look and can be found here .
The conference was somewhat eye opening for me as someone in Artificial Intelligence/Machine Learning to see how much work is still going in to making math programming optimization methods more and more powerful. It seems that at the very least these methods should be used for comparison when presenting clustering or planning results. Even better would be to increase the collaboration between these communities on using the best parts of different methods.
Here are some highlights from what I saw :
Rahul Jain at USC on MDPs for smart power grids as Linear Programs. Using the occupancy measure, how often states are visited, as a proxy for optimizing the policy directly. Modelled using conditional values as risk.
Michael Trick from CMU does the yearly scheduling for Major League Baseball amongst other things. He gave a very entertaining talk on how far LP solvers like CPLEX have come and how the process of many practitioners has shifted from trying to find ways to make the problem smaller, to trying to find ways to provide enough hints so that the highly optimized solvers can find better solutions.
Warren Powell from Princeton spoke on general optimization techniques revising the tutorial he gave in Denmark last summer at ICS 2012 (The other ICS that is.). He also spoke on work their lab at Princeton is doing on management of power grids in real time where some of the relevant variables are highly stochastic such as weather or the hourly spot pricing for electricity.
A fascinating talk by Victor Zavala of Argonne National Labs on the need to optimize cooling in thermal power generation like nuclear or coal plants. This is hard because it relies on ready access to cool water so droughts, rain and humidity are actually very relevant for planning how to run your power plants.
Nathaneal Brown from Sandia National Labs on the problem of planning maintenance of bridges and other urban infrastructure in such a way that effect of major earthquakes will be minimized. They consider maintaining multiple paths between major population centres and hospitals, etc.
Sarah Nurre at Renessealar Polytechnic Institute has an interesting problem of real time scheduling of power line restoration after hurricanes where requests arrive in real time but planning decisions about staff and materials need to be made beforehand and the goal is to restore power as quickly as possible.
Of course, I was there so I was presenting my own work in this area which is on policy gradient search methods for planning in spatiotemporal problems like forest management.
Some Light Reading For the Weekend
If you are looking for some light reading for the weekend the first mandated US National Climate Assessment has been released. It’s just 400 pages and includes the latest scientific knowledge on a range of topics in climate chance and sustainability with predictions and impacts on the climate in the US and at at least some data about Canada as well on brief perusal.
Upcoming
Conference: AAAI Conference on Artificial Intelligence with a special track on Computational Sustainability for the third year in a row. AAAI is Co-located this year with UAI2013. Deadlines: (Last Chance!) Abstracts: Jan 19, 2013. Papers: Jan 22, 2013. Time and Place: July 14-18, 2013 in Bellevue, Washington, USA (near Seattle).
Conference: International Joint Conference on Artificial Intelligence The theme of IJCAI 2013 is “AI and computational sustainability“. The conference will include for the first time a special track dedicated to papers concerned with all the aspects of Computational Sustainability. Deadlines: Abstract: January 26, 2013. Paper: January 31, 2013. Time and Place: Beijing, China, on August 3-9, 2013.
(NEW) Conference:International Green Computing Conference including research on a broad range of topics in the fields of sustainable and energy-efficient computing, and computing for a more sustainable planet. Deadline: February 15, 2013 Time and Place: Arlington, Virginia, USA. June 27-29, 2013.
Workshop: Energy Aware Software-Engineering and Development (EASED) provides a broad forum for researchers and practitioners to discuss ongoing works, latest results, and common topics of interest regarding the improvement of software induced energy consumption. Deadline: March 15, 2013 Time and Place: Carl von Ossietzky University, Oldenburg, Germany
Conference : ICT for Sustainability Conference : aims to bring together leading researchers to take stock of the role of ICT in sustainability, to create an interdisciplinary synopsis, to inspire new approaches to unleash the potential of ICT for sustainability, and to improve methodologies of evaluating, developing, and governing the effects of ICT systems on the sustainability of societal and environmental systems. Deadline: passed. Time and Place: ETH Zurich, Switzerland. February 14-16, 2013.
 This week in Québec City the Twenty-Eighth AAAI Conference is being held and for the fourth year running there is a special track on Computational Sustainability. The range of talks look at ways to apply and extend ideas in Artificial Intelligence and Machine Learning for solving complex problems in Electric Vehicle Management, Bird Tracking, Disease Mapping, Power Management and Urban Emergency Preparedness.
This week in Québec City the Twenty-Eighth AAAI Conference is being held and for the fourth year running there is a special track on Computational Sustainability. The range of talks look at ways to apply and extend ideas in Artificial Intelligence and Machine Learning for solving complex problems in Electric Vehicle Management, Bird Tracking, Disease Mapping, Power Management and Urban Emergency Preparedness.